document source in Markdown format
Introduction
Why? What for?
Workflow overview
Citation profile: user interface
The most interesting document
Per-document screens: identified and potential tabs
“Auto suggestions” screen
Document list screen
Refused citations screen
Citation profile overview screen
Automatic citation profile update
Automatic Update Preferences screen
Notification emails
Citations data input
Citations data output
Administration and configuration
Input data
Citations screens parameters
Technical implementation details / developer’s guide
Processing the citations data
Citations table
Citation string normalization:
Cutting out the editors part
Search for citations and ACPU
Automatic citation profile update
Search workflow
Citation to document similarity
Similarity assessment function interface
The default citation-document
similarity assessment algorithm
Citation suggestions
Citation to document similarity table: cit_doc_similarity
other citation suggestions table: cit_sug
Old suggestions table: cit_old_sug
Similarity matrix
Data structure
main matrix operations
Userdata structure
Storing and passing citations around
Modules
ACIS::Citations
ACIS::Citations::Utils
ACIS::Citations::Input
ACIS::Citations::Suggestions
ACIS::Citations::SimMatrix
ACIS::Citations::Search
ACIS::Web::Citations::Profile
ACIS::Web::Citations
ACIS::Citations::AutoUpdate
Other notes
SysProf table profile parameters
Consistency maintentance
Database maintenance
Authors have a strong desire to find out
We want to give authors such data. And that is our reason no. 1.
This is not only to caress their vanity, but also to support further research dialogue, especially when this data is published in an accessible and reusable way.
Automated citation parsing and indexing systems exist (CiteSeer, also see Open Citation) and are able to provide such data, when applied to an appropriate collection. But automated citation processing is technically a very complicated task and mistakes are not rare.
But we believe that the authors themselves can verify and filter automatically produced citation data. Thus, with the authors’ help, we will get improved citation data. Now that is our reason no. 2.
By publishing the resulting data in a simple, documented form, an ACIS service will support creation of additional services based on that data.
Therefore, we follow a two-level approach. First level: autonomous citation indexing. Citations get parsed, extracted and indexed with an automated reference and citation parsing system. That happens outside ACIS, by systems like CiteSeer.
Second level happens in ACIS: human users review, validate and filter the data.
Here is what happens and what we do with citations.
A citation indexing service processes the same set of data on which an ACIS service is running. It parses the documents’ full texts and finds citations and tries to identify, which citations point to which documents. It then encodes its resuls, i.e. the citations data, in the specified input format.
The data is then supplied to the ACIS service. (How the data is transfered is out of the scope of our concern.) Service administrator will have to get things configured for this.
Then ACIS starts offering citations to its users and they create their own citation profiles. This means they identify citations as pointing to their own particular documents. They reject some citations which are not relevant to them. At this stage ACIS software tries hard to be helpful and make the process easy.
As a result of this interaction, ACIS collects improved citations data, and includes it into the personal data that ACIS exports. Third-party projects then may use it for building additional user services based on the data.
In this document we first describe the user interface, then the data formats, then the administrator’s configuration parameters. Technical implementation details are probably interesting to only a few; therefore, they come last.
Citation profile is a part of the ACIS web interface, where the users deal with citations. The users’ are given power to:
review citations that have been identified as referring to their works;
certify that particular citations point to their particular documents, with ability to review their choices and correct errors in their earlier-made choices;
refuse errorneously-suggested citations and review previously refused citations to undo errornously-refused items.
ACIS will search for citations in the database (among the data provided on input), attempt to match the citations to the documents of the user’s research profile, and offer them to the user for review and identification.
Design requirements. The screens of the citation profile should look and work similar to those of the research profile. Consistency has to be maintained.
Before we offer any citations to the user for identification, we will assess all the citations found for her. By matching (comparing) the citations to the descriptions of the documents of her research profile, we will find:
which document is the most interesting in a sense that it has most potential new citations pointing to it (weighted by their respective similarity measure);
which citations more closely resemble which document’s description.
This will give us the order, in which to present the documents and citations to the user: we will always show the most interesting document first (see auto suggestions) and the most relevant citations at the top. Depending on the similarity level, some of the citations will be pre-selected for identification by default.
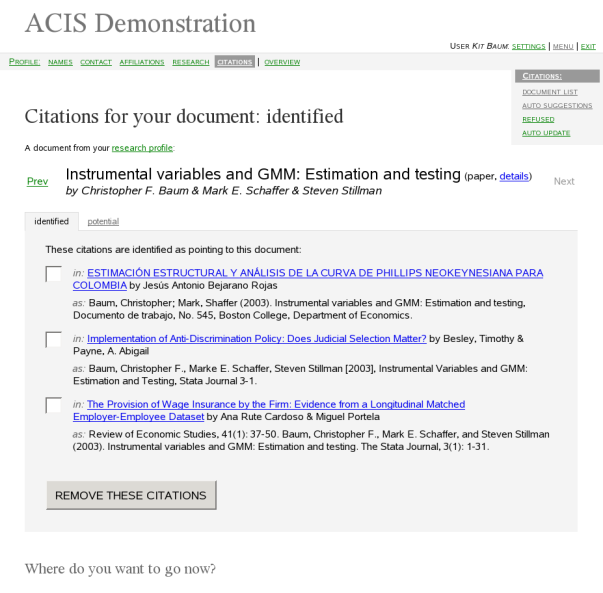
Main work on citations happens on per-document screens, which means the user operates on citations for one particular item of her research profile at a time. The title and other details of the document are shown in large type at the top of the screen. Then there are two tabs on the page, labeled identified and potential.
In the identified tab, the user sees the list of all the citations that she has identified to the document. She can remove the citations that have been mistakenly identified. Such citations become avalailable for all documents of her (to which they match). They are then displayed as new citations, even in the potential tab for the current document.
In the potential tab we offer citations for user to identify. We only offer citations that we found similar to the description of the document.
Two kinds of citations may be offered: “new” and “old”. Old citations are the ones that we have already suggested to the user for this particular document in the past. (Thus a citation can only be old for a certain document.) A citation becomes old only after we suggested it to a user and the user submitted the form, but did not select this citation for inclusion. If she didn’t submit the form, which included this citation as new, we will still consider it new.
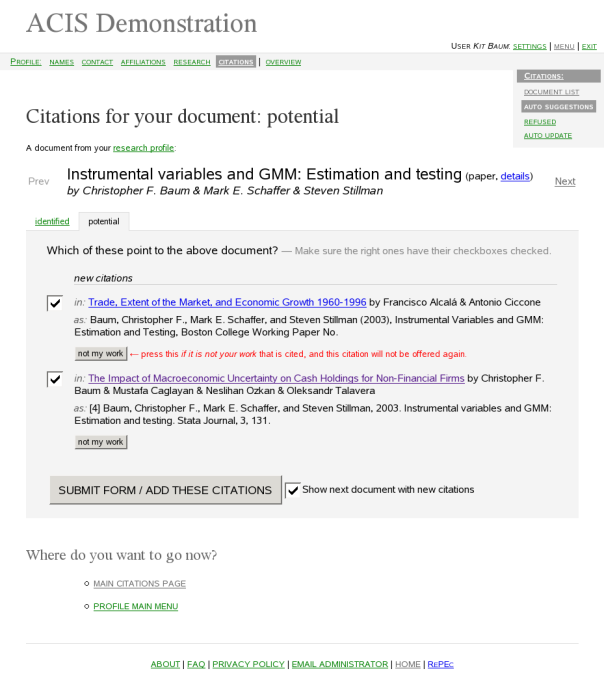
We present the potential citations as shown in the prototype page linked above. The old citations will not be shown by default, only if the user requests it. Both old and new citations are ordered by decreasing similarity of the citation to the document. Some of the new citations, i.e. for which the similarity is higher than a certain threshold, will have the checkbox checked by default. The threshold level is configureable by system administrator.
The “Not my work” button removes a citation from the pool of potential citations for all the documents, and puts it into the refused citations list.
If the user presses the SUBMIT FORM button, all checked citations will be identified as pointing to that document. They will no longer be suggested for identification to other documents.
When there is at least one other document with new citations for it, we show a checkbox near the submit button, labeled “Show next document with new citations”. This checkbox will be checked by default if the current page offers any new citations. If the checkbox is checked when the form is submitted, we process the user’s choices and then redirect her to the next most interesting document.
If we have no potential citations for the document in question, we will show a message saying:
We have no citations to suggest for this document at this time.
When the system has some new unidentified citations for a user, and the user enters citation profile, we take the user to the AUTO SUGGESTIONS screen.
On it we always show the user the potential tab for a document with new citations. The document we show there is always the most interesting document. When user deals with these citations, another document would (very likely) become the most interesting. If she doesn’t uncheck the “move on” checkbox (“Show next document with new citations”), she would be shown the next most interesting document immediately after dealing with the current one. If the user follows this simple procedure, she will be taken through all the new potential citations for her documents, going through the most cited documents first.
The screen is always accessible via “auto suggestions” link-item in the right-hand top corner menu (under “Citations:”). So if user deviates from the procedure, it would be easy for her to continue. When displaying this screen, we highlight this link as a link to the current screen (and it won’t be a link).
For navigation between the documents the users have the “Next” and “Prev” links to the right and left of the document title (respectively). The “Next” link leads to the second most interesting document (if there is such a document).
What if there are no new citations?
If there are no documents for which we have any new citations, we show a brief screen with this message:
We are sorry to tell you that we have no potential
citations data for the documents in your research
profile.
If the user has no documents in the research profile, we show this message instead:
We are sorry to tell you that we have no potential
citations data for the documents in your research
profile, because your research profile is empty.
A table of all documents (research profile items) is shown on the “Document list” screen. It also provides numbers of citations identified to each document and number of new potential citations for each. Each line in the table provides both a link to the identified tab for that document and a link to the potential tab for it. The table may be sorted by the number of citations identified, or by the number of new potential citations for it.
Each document in the table will be presented by a title and a link to its further details.
The screen will also display the total number of identified citations.
On the Refused Citations screen users will deal with citations, for which user has pressed the “Not my work” button in the past. Those are the citations to works that the user has told us she is not an author of. She can remove citations, which then may be suggested to the same or other documents, depending on similarity found.
The main page of the citation profile gives a brief introduction and overview of the profile, with links to appropriate screens. This is similar to research profile overview screen. It offers links to the document list screen, to the auto suggestions screen (i.e. the most interesting document, if there is such a document at the time), and a link to the refused citations screen.
If there are new potential citations for some documents of a person, on the first enterance of the person into his citation profile, we redirect him to the auto suggestions page. But we do this only once per user session to avoid confusion.
Similar to the automatic research profile update, ACIS may sometimes update citation profiles for its users automatically. There are three such cases, when a citation can be added to the profile:
when a citation has been identified by the autonomous citation indexing service as pointing to a document of a user;
when we find that a new citation has a very high similarity to one of the documents of a user (as measured by the citation-to-document similarity assessment algorithm);
when two or more users have collectively authored a document, and that document is included into their research profiles, and one of the users has identified a citation as pointing to that document.
Then if the citation profile is updated, an email message is sent to the user (the owner of the profile) to notify her about the changes.
Some users most certainly won’t trust automatic changes or experience problems with it. Therefore, even though these features are enabled by default for all users, they can disable them. To disable these features, users use the Automatic Update Preferences screen. There is a similar screen in the research profile.
Difference between the first two cases of automatic citaiton addition is difficult to explain to users, and, therefore, it will be regulated by one user option.
The screen offers several yes/no questions-options.
AUTOMATIC CITATION PROFILE UPDATE
We can do automatic additions to your citation profile
in certain cases (explained below). An email
notification will be sent to you every time we change
your profile automatically. Here you may disable or
enable automatic changes to your profile.
When we know with high certainty that a new citation is
pointing to one of your works, should we automatically
add it to your identified citations? (You can always fix
it later, if a mistake happens.)
(*) yes
( ) no
When one of your co-authors has identified a citation as
pointing to your co-authored document, should we add
it to your profile also?
(*) yes
( ) no
The notification message will arrive from address:
acis@somewhere.org
Please add this address to your spam filter's whitelist
to make sure it does not stop these messages.
A link to this screen is labeled “AUTO UPDATE” in the citation profile menu (right-hand top corner navigation menu).
Automatic citation profile update and research profile update are separate functions of ACIS. Notification messages generated by these functions are separate.
To avoid bombarding users with notification emails, we don’t do automatic updates for a single personal profile more often than once in two weeks.
An automatic citation profile update notification message may look like this:
From: acis@somewhere.org
To: A.U. Thor <author@email.edu>
Subject: [GAS] citations automatically added
Dear A.U. Thor,
This is an automatic message from Great Author
Service. You don't need to reply.
We ran a search for citations to your documents in our
service and found some, which we think point to these
your documents, see below. We added these citations to
your profile, but if there's an error, you can fix it.
Document:
Imperfect Capital Markets Need Not be Inefficient
paper by David Webb & David De Meza
http://ideas.repec.org/p/fmg/fmgdps/dp0007.html
Citations:
* in: Exact joint forecasts for vector aggressive
models by Lu-Sam Xiu
http://ideas.repec.org/p/xiu/xiudps/2001.html
cited as: Webb D., De Meza D. 1999. Imperfect
Capital Markets Need Not be Inefficient. Financial
Markets Group, Discussion papers.
...
To review and correct these items, log into your profile
at this address:
http://gas.somewhere.org/citations/doclist
If necessary, review and change your preferences with
regard to future automatic citation profile updates at:
http://gas.somewhere.org/citations/autoupdate
Your password in our service is:
supersecret
---
The message was automatically generated by Great Author Service.
http://gas.somewhere.org/
Data comes from automatic reference and citation parsing systems, e.g. CitEc, CiteSeer.
For ACIS to process and use citation data, the data must be encoded in the Academic Metadata Format and the system must be configured appropriately.
Two kinds of citations are expected in the input data:
Identified are the citations, which have an autonomously identified citation targets. That is, the software on the citations data provider side has found that such a citation points to a particular document in the same set of documents and the identifier of that cited document is included with the citation itself.
Therefore, the unidentified citations are those, which point to an unknown document, which may be present in the document database of ACIS or may not be present.
Identified citations will be encoded in this way:
<text ref="text">
<references>
<acis:referencestring> text of citation </acis:referencestring>
<text ref="text2"/>
</references>
</text>
where acis is a prefix for the namespace “http://acis.openlib.org/” and text2 is the identifier of the document that the citation points to. The citation string comes in the text content of the foreign-namespace element referencestring.
While it is technically valid AMF to have several text nouns as children of the references verb, ACIS will only accept the first one. Thus
<text ref="text">
<references>
<acis:referencestring> text of citation 1 </acis:referencestring>
<text ref="text1"/>
<acis:referencestring> text of citation 2</acis:referencestring>
<text ref="text2"/>
</references>
</text>
will ignore citation 2. To get both citation 1 and citation 2, you have to say
<text ref="text">
<references>
<acis:referencestring> text of citation 1 </acis:referencestring>
<text ref="text1"/>
</references>
<references>
<acis:referencestring> text of citation 2</acis:referencestring>
<text ref="text2"/>
</references>
</text>
Unidentified citations are written as:
<text ref="text">
<reference>
<literal> unidentified citation </literal>
</reference>
</text>
If data comes in such a form:
<text ref="text">
<references>
<text ref="text2"/>
</references>
</text>
then nothing is being done with it.
We will output citations data as part of the personal profile AMF datafiles. The citations data will be added to the document data, i.e. the research profile. Personal AMF data always includes a person noun. Here is an incomplete example showing how would identified citations added to the documents data:
<person id="donald_duck">
<name>Donald Duck</name>
<isauthorof>
<text ref="text0">
<isreferencedby>
<text ref='text4'/>
</isreferencedby>
</text>
</isauthorof>
<isauthorof>
<text ref="text20">
<isreferencedby>
<text ref='text5'/>
</isreferencedby>
<isreferencedby>
<text ref='text6'/>
</isreferencedby>
</text>
</isauthorof>
</person>
The identified citations would not be displayed on the personal profile pages, generated for each profile in ACIS.
Citation data can be “fed” to an ACIS service only in the form of a collection of metadata files.
That means you should configure a new metadata collection via the metadata-collections parameter. To make ACIS aware, that it should expect citation data in it, set the collection’s type (metadata-X-type parameter) to “CitationsAMF”.
It may look like this:
metadata-collections='RePEc CitEc'
metadata-RePEc-home=/data/RePEc/amf
metadata-RePEc-type=AMF
metadata-CitEc-home=/data/CitEc/amf
metadata-CitEc-type=CitationsAMF
The data files must have .amf.xml name
extension to be processed by ACIS.
The citation profile is enabled and configured via the the main.conf configuration file. (Just as every other part of the ACIS web interface.)
See Citations screens parameters in another document.
The data processing flow. RePEc::Index and RePEc::Index::Collections::CitationsAMF to ACIS::Citations::Input via the collection’s proc parameter.
RePEc::Index::Collections::CitationsAMF uses AMF::Parser to parse the files. Citations originating from a document will comprise one record.
ACIS::Citations::Input saves the data into the citations table and removes disappeared citations.
find the document’s sid and details URL
load from the citations table all the known citations originating from the document
find new / disappeared
normalize new
remove editor names from new
save new
remove disappeared
The fields:
cnid SERIAL
clid CHAR(38) NOT NULL PRIMARY KEY:
srcdocsid + ‘-’ + checksum (MD5 checksum of the original citation
string in base64 encoding - 22 chars)ostring TEXT NOT NULL
nstring VARCHAR(255) NOT NULL
trgdocid VARCHAR(255)
FULLTEXT INDEX (nstring), INDEX (trgdocid)
The original citation string may contain editor names, which we don’t want, because they will cause the citation to be found mistakenly for authors.
The regular expression:
s/\b((I|i)n\W.+?\Wed\..*)$//
should do the trick.
Via APU. ACIS::APU -> ACIS::Citations::AutoUpdate -> ACIS::Citations::Search
Former ARPU has been extended to cover citations and they now jointly known as APU: automatic profile update.
APU has a number of configuration parameters:
minimum-apu-period-days minimum APU period (default: 3
weeks or 21 day(?)).
echo-apu-mails, boolean — whether to send a copy of
the APU mails to the admin or not.
disable-citation-mails, boolean — whether to send
citation mails at all.
ACPU itself includes 3 things:
Every time ACPU is done, a timestamp is added to the sysprof table for that record (‘last-auto-citations-time’).
When APU is about to run, it chooses those records, which have their ACPU or ARPU timestamps oldest, just as it is now done for ARPU only.
For each research profile item of the user, we do something like:
select * from citations where trgdocid = 'repec:fdd:fodooo:555';
and it finds us citations which where pre-identified as pointing to that document. Pre-identified means identified by the citations data provider.
For each name variation of the user we do:
select * from citations where MATCH (nstring) AGAINST
('JOHN MALKOVICH' IN BOOLEAN MODE)
(this is a simplified variation of the actual query.)
Then we exclude (from what’s found) the already known: identified and refused citations. Then we exclude citations already suggested.
Then those that are left we compare to the RP documents and look at what came out of it. If anything interesting came out — we add those. But we do not add a citation if it has already been suggested in the past, i.e. if it is old. Ok, let’s look closer at it.
THE WORKFLOW
by the person’s research profile documents:
find citations, that were pre-identified for a document
filter out identified citations
filter out refused citations
filter out old, suggested in the past items (cit_old_sug table)
then, for the rest of citations:
the person’s name:
find citations, that match the person’s name variations
filter out identified citations
filter out refused citations
filter out old, suggested in the past items (cit_old_sug table)
then, for the rest of citations:
compare them to the person’s documents
comparison results would be written to the cit_doc_similarity table
then, if auto-add is enabled for this profile
find which of the new citations have high similarity measure to a document (and which have the highest, if there’s several of them)
auto add them, if preferences allow
The citation-document similarity function (see citation-document-similarity-func) will be called by ACIS like this:
$sim = func( CIT, DOC );
where CIT is a reference to a citation record, DOC is a reference to a document record and $sim is a similarity value returned by the function.
is a reference to a hash:
{ ostring => CITSTR,
nstring => NORCITSTR }Here CITSTR is the original citation string, and NORCITSTR is the normalized citation string.
is a reference to a hash:
{ title => TITLE,
authors => [ AUTHOR1NAME, AUTHOR2NAME, ... ],
type => TYPE,
location => LOCATION
}Here TITLE is the work’s title (a string), AUTHOR1NAME, AUTHOR2NAME and so on are the names of the authors (strings), and TYPE is one of “article”, “paper”, “book”, “software”, “chapter”, “text” (when no particular type is known).
LOCATION is a string built by joining the following items: the series or journal name, the paper’s number in the series (if it is present), the issue/volume/pages. For AMF we can take all the adjectives of the serial adjective container.
For a given document and a given citation:
Look at the author names first. Split the names of the authors of the document into a list of words, strip all non-letter non-whitespace characters and then strip single whitespace-separated letters from it.
We then search for approximate matches for each of these words in the normalized citation string. (String::Approx) If there is a match for any of the author-name-words, it is an “author pass”. Otherwise, the match is aborted with zero similarity measure returned.
foreach ( @names ) {
if ( amatch( $_, $citation ) ) {
$pass = 1;
last;
}
}If the document is an author pass, it will be ranked according to the string similarity of the title only, see next point.
Compare titles. Take the normalized citation string and take the normalized title of the research item. Find where in the citation string the first word of the title is present.
Take as many characters of the citation string as there are in the title and compare them to the work’s title (with String::Similarity).
(Alternatively, find where in the citation string the last word of the title is present and take a substring from start to end. Compare in the same way.)
(Alternatively, do a String::Approx amatch on the citation string, with the document’s title used as the pattern. — No, this will result in just yes/no value, but we need a numeric measure.)
Get the comparison result as a number between 0 and 1.
Table cit_doc_similarity fields:
cnid BIGINT UNSIGNED NOT NULL
dsid CHAR(15) NOT NULL
similar TINYINT NOT NULL
time DATETIME NOT NULL
PRIMARY KEY (cnid,dsid)
Table cit_sug fields:
cnid BIGINT UNSIGNED NOT NULL
dsid CHAR(15) NOT NULL
reason CHAR(20) NOT NULL
time DATETIME NOT NULL
PRIMARY KEY (cnid,dsid,reason)
Table cit_old_sug fields:
psid CHAR(15) NOT NULL dsid CHAR(15) NOT NULL
cnid BIGINT UNSIGNED NOT NULL
PRIMARY KEY (psid,dsid,cnid)
matrix:
new (hash):
old (hash):
totals_new (hash):
doclist (list): list of document sids in the order of decreasing similarity (based on totals_new)
citations (hash):
psid: personal record short id
“dxx44” — research profile item’s sid
$matrix -> {new} {dxx44}[0] — the first of the new citations suggested for research profile item dxx44
$matrix -> {new} {dxx44}[1]->{similar} — similarity of the second citation’s to dxx44 document
$matrix -> {citations} {‘dcen4-n6Ci5dmzFdBAtQx4K+mEjg’} {dxx44} — array of where this citation is suggested.
$matrix -> {citations} {‘dcen4-n6Ci5dmzFdBAtQx4K+mEjg’} {dxx44}[0][0] — ‘new’ or ‘old’
$matrix -> {citations} {‘dcen4-n6Ci5dmzFdBAtQx4K+mEjg’} {dxx44}[0][1] — reference to the particular suggestion hash
Similarity values in the matrix and in the cit_doc_similarity table are all in the percent scale. They are produced by multiplying the similarity values (calculated by the cit-to-document comparison function) by 100.
load the matrix
calculate totals
get most interesting document (dsid)
consider new citations
remove citation
citation status change new to old
The citations branch of the userdata structure:
identified: hash
refused: a list of citations
meta: hash
co-auth-auto-add: auto co-authorship update optionauto-identified-auto-add: auto pre-identified update optionauto-add-similarity-threshold: a numberlast-searched-nameset-date: date of the last searched name variations setpotential new & old citations we will store in the citdocsimilarity, citsug and citold_sug tables
Each citation item in the userdata is a hash with these items:
Citations will be stored as:
citation table records
in-memory suggestions
userdata items (see above)
Basically, the citations will go from 1 to 2 and from 2 to 3. At each step, some hash keys may be added to a citation or may be removed.
But sometimes a citation is removed from userdata and then it may be re-considered as a suggestion (3->2).
normalize_string( string )
build_citations_index( citlist, [index] ); - build a hash of [ cnid: citation ] pairs ???
get_document_authors(); - for co-authors’ claims
cit_document_similarity( cit, doc ) — default cit-doc similarity func
and other useful stuff
use ACIS::Citations::Utils;
process_citation( cit ) - normalize, cut the editors, calculate the checksum
save_citation( cit )
check_citation( cit ) - reload citation from the citations table or return undef otherwise
use ACIS::Citations::Suggestions;
exported:
object methods:
most_interesting_doc( );
remove_citation( $matrix, $cit );
…
internal:
use ACIS::Citations::Utils; use ACIS::Citations::Suggestions;
exportable:
search_for_document( id ) - find pre-identified citations
search_for_personal_names( names )
…
use ACIS::Citations::Input; use ACIS::Web::SysProfile;
acis_citations_enabled() - check that citations-profile parameter has a true value in main.conf; returns true or false [15 min]
prepare() [30 min]
prepare_identified() [30 min]
process_identified() [60 min]
prepare_potential() [30 min]
process_potential() [60 min]
process_not_my_work() [30 min]
prepare_refused() [30 min]
process_refused() [60 min]
auto_suggestions() [30 min]
prepare_doclist() [30 min]
last profile check time (seconds since the epoch):
last-cit-prof-check-time
last citation search date/time (seconds):
last-auto-citations-time
Every once in a while we check that every citation that is mentioned in the personal profile is still present in the citations table, and clear it, if it isn’t there.
We will remember the date of last cleaning run and at each user login
(real or in APU) we will see if the profile needs cleaning already.
(last-cit-prof-check-time in sysprof).
In a similar way, we ensure that every document for which we have the identified citations is still present in the database.
It would be highly desirable to backup the citations, citations_deleted and other related tables regularly. It is important for consistency of the data and stability of the user profiles.
$Id$
Generated: Wed Aug 29 22:59:09 2007
ACIS project, acis@openlib.org